FAQ for this chapter: http://jeason.gitcafe.io/ppt/pintos_faq_3
3. Project: Threads
In this assignment, we give you a minimally functional thread system. Your job is to extend the functionality of this system to gain a better understanding of synchronization problems.
You will be working primarily in the ‘threads’ directory for this assignment, with some work in the ‘devices’ directory on the side. Compilation should be done in the ‘threads’ directory. Before you read the description of this project, make sure you have read all of the Chapter 1.
3.1 Background
3.1.1 Pintos Loadding
This section covers the Pintos loader and basic kernel initialization. We recommend using “tags” to follow along with references to function and variable names.
3.1.1.1 The Loader
The first part of Pintos that runs is the loader, in ‘threads/loader.S’. The PC BIOS loads the loader into memory. The loader, in turn, is responsible for finding the kernel on disk, loading it into memory, and then jumping to its start. It’s not important to understand exactly how the loader works, but if you’re interested, read on. You should probably read along with the loader’s source. You should also understand the basics of the 80x86 architecture as described by chapter 3, “Basic Execution Environment”, of [IA32-v1].
The PC BIOS loads the loader from the first sector of the first hard disk, called the master boot record (MBR). PC conventions reserve 64 bytes of the MBR for the partition table, and Pintos uses about 128 additional bytes for kernel command-line arguments. This leaves a little over 300 bytes for the loader’s own code. This is a severe restriction that means, practically speaking, the loader must be written in assembly language.
The Pintos loader and kernel don’t have to be on the same disk, nor does is the kernel required to be in any particular location on a given disk. The loader’s first job, then, is to find the kernel by reading the partition table on each hard disk, looking for a bootable partition of the type used for a Pintos kernel.
When the loader finds a bootable kernel partition, it reads the partition’s contents into memory at physical address 128 kB. The kernel is at the beginning of the partition, which might be larger tan necessary due to partition boundary alignment conventions, so the loader reads no more than 512 kB (and the Pintos build process will refuse to produce kernels larger than that). Reading more data than this would cross into the region from 640 kB to 1 MB that the PC architecture reserves for hardware and the BIOS, and a standard PC BIOS does not provide any means to load the kernel above 1 MB.
The loader’s final job is to extract the entry point from the loaded kernel image and transfer control to it. The entry point is not at a predictable location, but the kernel’s ELF header contains a pointer to it. The loader extracts the pointer and jumps to the location it points to.
The Pintos kernel command line is stored in the boot loader. The pintos program actually modifies a copy of the boot loader on disk each time it runs the kernel, inserting whatever command-line arguments the user supplies to the kernel, and then the kernel at boot time reads those arguments out of the boot loader in memory. This is not an elegant solution, but it is simple and effective.
3.1.1.2 Low-Level Kernel Initialization
The loader’s last action is to transfer control to the kernel’s entry point, which is start() in ‘threads/start.S’. The job of this code is to switch the CPU from legacy 16-bit “real mode” into the 32-bit “protected mode” used by all modern 80x86 operating systems.
The startup code’s first task is actually to obtain the machine’s memory size, by asking the BIOS for the PC’s memory size. The simplest BIOS function to do this can only detect up to 64 MB of RAM, so that’s the practical limit that Pintos can support. The function stores the memory size, in pages, in global variable init_ram_pages.
The first part of CPU initialization is to enable the A20 line, that is, the CPU’s address line numbered 20. For historical reasons, PCs boot with this address line fixed at 0, which means that attempts to access memory beyond the first 1 MB (2 raised to the 20th power) will fail. Pintos wants to access more memory than this, so we have to enable it.
Next, the loader creates a basic page table. This page table maps the 64 MB at the base of virtual memory (starting at virtual address 0) directly to the identical physical addresses. It also maps the same physical memory starting at virtual address LOADER_ PHYS_BASE, which defaults to 0xc0000000 (3 GB). The Pintos kernel only wants the latter mapping, but there’s a chicken-and-egg problem if we don’t include the former: our current virtual address is roughly 0x20000, the location where the loader put us, and we can’t jump to 0xc0020000 until we turn on the page table, but if we turn on the page table without jumping there, then we’ve just pulled the rug out from under ourselves.
After the page table is initialized, we load the CPU’s control registers to turn on protected mode and paging, and set up the segment registers. We aren’t yet equipped to handle interrupts in protected mode, so we disable interrupts. The final step is to call main().
3.1.1.3 High-Level Kernel Initialization
The kernel proper starts with the main() function. The main() function is written in C, as will be most of the code we encounter in Pintos from here on out.
When main() starts, the system is in a pretty raw state. We’re in 32-bit protected mode with paging enabled, but hardly anything else is ready. Thus, the main() function consists primarily of calls into other Pintos modules’ initialization functions. These are usually named module_init(), where module is the module’s name(e.g. thread_init()), ‘module.c’ is the module’s source code, and ‘module.h’ is the module’s header.
The first step in main() is to call bss_init(), which clears out the kernel’s “BSS”, which is the traditional name for a segment that should be initialized to all zeros. In most C implementations, whenever you declare a variable outside a function without providing an initializer, that variable goes into the BSS. Because it’s all zeros, the BSS isn’t stored in the image that the loader brought into memory. We just use memset() to zero it out.
Next, main() calls read_command_line() to break the kernel command line into arguments, then parse_options() to read any options at the beginning of the command line. (Actions specified on the command line execute later.)
thread_init() initializes the thread system. We will defer full discussion to our discussion of Pintos threads below. It is called so early in initialization because a valid thread structure is a prerequisite for acquiring a lock, and lock acquisition in turn is important to other Pintos subsystems. Then we initialize the console and print a startup message to the console.
The next block of functions we call initializes the kernel’s memory system. palloc_init() sets up the kernel page allocator, which doles out memory one or more pages at a time. malloc_init() sets up the allocator that handles allocations of arbitrary-size blocks of memory. paging_init() sets up a page table for the kernel.
The next set of calls initializes the interrupt system. intr_init() sets up the CPU’s interrupt descriptor table (IDT) to ready it for interrupt handling, then timer_init() and kbd_init() prepare for handling timer interrupts and keyboard interrupts, respectively. input_init() sets up to merge serial and keyboard input into one stream. In projects 2 and later, we also prepare to handle interrupts caused by user programs using exception_init() and syscall_init().
Now that interrupts are set up, we can start the scheduler with thread_start(), which creates the idle thread and enables interrupts. With interrupts enabled, interrupt-driven serial port I/O becomes possible, so we use serial_init_queue() to switch to that mode. Finally, timer_calibrate() calibrates the timer for accurate short delays.
Boot is complete, so we print a message.
Function run_actions() now parses and executes actions specified on the kernel command line, such as run to run a test or a user program.
Finally, if ‘-q’ was specified on the kernel command line, we call shutdown_power_off() to terminate the machine simulator. Otherwise, main() calls thread_exit(), which allows any other running threads to continue running.
For more information, read about MIT's JOS Lab1: Booting a PC
3.1.1.4 Physical Memory Map
| Memory Range | Owner | Contents |
|---|---|---|
| 00000000–000003ff | CPU | Real Mode interrupt table. |
| 00000400–000005ff | BIOS | Miscellaneous data area. |
| 00000600–00007bff | \ | \ |
| 00007c00–00007dff | Pintos | Loader. |
| 0000e000–0000efff | Pintos | Stack for loader; kernel stack and struct thread for initial kernel thread. |
| 0000f000–0000ffff | Pintos | Page directory for startup code. |
| 00010000–00020000 | Pintos | Page tables for startup code. |
| 00010000–00020000 | Pintos | Kernel code, data, and uninitialized data segments. |
| 000a0000–000bffff | Video | VGA display memory. |
| 000c0000–000effff | Hardware | Reserved for expansion card RAM and ROM. |
| 000f0000–000fffff | BIOS | ROM BIOS. |
| 00100000–03ffffff | Pintos | Dynamic memory allocation. |
3.1.2 Thread
The next step is to read and understand the code for the initial thread system. Pintos already implements thread creation and thread completion, a simple scheduler to switch between threads, and synchronization primitives (semaphores, locks, condition variables, and optimization barriers).
Some of this code might seem slightly mysterious. If you haven’t already compiled and run the base system, as described in the introduction, you should do so now. You can read through parts of the source code to see what’s going on. If you like, you can add calls to printf() almost anywhere, then recompile and run to see what happens and in what order. You can also run the kernel in a debugger and set breakpoints at interesting spots, single-step through code and examine data, and so on.
3.1.2.1 struct thread
The main Pintos data structure for threads is structthread, declared in ‘threads/thread.h’.
struct thread
Represents a thread or a user process. In the projects, you will have to add your own members to struct thread. You may also change or delete the definitions of existing members. Every struct thread occupies the beginning of its own page of memory. The rest of the page is used for the thread’s stack, which grows downward from the end of the page. It looks like this:
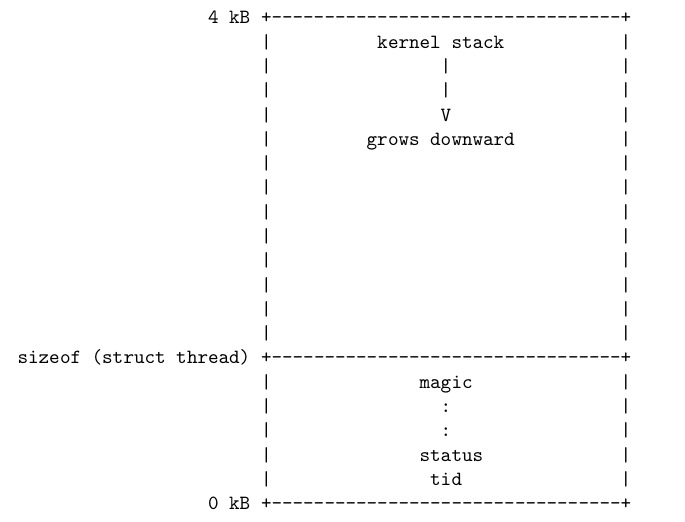
This has two consequences. First, struct thread must not be allowed to grow too big. If it does, then there will not be enough room for the kernel stack. The base struct thread is only a few bytes in size. It probably should stay well under 1 kB. Second, kernel stacks must not be allowed to grow too large. If a stack overflows, it will corrupt the thread state. Thus, kernel functions should not allocate large structures or arrays as non-static local variables. Use dynamic allocation with malloc() or palloc_get_page() instead.
tid_t tid
The thread’s thread identifier or tid. Every thread must have a tid that is unique over the entire lifetime of the kernel. By default, tid_t is a typedef for int and each new thread receives the numerically next higher tid, starting from 1 for the initial process. You can change the type and the numbering scheme if you like.
enum thread_status status
The thread’s state, one of the following:
| State | Description |
|---|---|
| THREAD_RUNNING | The thread is running. Exactly one thread is running at a given time. thread_current() returns the running thread. |
| THREAD_READY | The thread is ready to run, but it’s not running right now. The thread could be selected to run the next time the scheduler is invoked. Ready threads are kept in a doubly linked list called ready_list. |
| THREAD_BLOCKED | The thread is waiting for something, e.g. a lock to become available, an interrupt to be invoked. The thread won’t be scheduled again until it transitions to the THREAD_READY state with a call to thread_unblock(). This is most conveniently done indirectly, using one of the Pintos synchronization primitives that block and unblock threads automatically . |
| THREAD_DYING | The thread will be destroyed by the scheduler after switching to the next thread. |
- char name[16]
The thread’s name as a string, or at least the first few characters of it.
uint8_t* stack
Every thread has its own stack to keep track of its state. When the thread is running, the CPU’s stack pointer register tracks the top of the stack and this member is unused. But when the CPU switches to another thread, this member saves the thread’s stack pointer. No other members are needed to save the thread’s registers, because the other registers that must be saved are saved on the stack.
When an interrupt occurs, whether in the kernel or a user program, an struct intr_frame is pushed onto the stack. When the interrupt occurs in a user program, the struct intr_frame is always at the very top of the page.
int priority
A thread priority, ranging from PRI_MIN (0) to PRI_MAX (63). Lower numbers correspond to lower priorities, so that priority 0 is the lowest priority and priority 63 is the highest. Pintos as provided ignores thread priorities, but you will implement priority scheduling in this project.
struct list_elem allelem
This “list element”(More about how to use list?) is used to link the thread into the list of all threads. Each thread is inserted into this list when it is created and removed when it exits. The thread_foreach() function should be used to iterate over all threads.
struct list_elem elem
A “list element” used to put the thread into doubly linked lists, either ready_list (the list of threads ready to run) or a list of threads waiting on a semaphore in sema_down(). It can do double duty because a thread waiting on a semaphore is not ready, and vice versa.
uint32_t * pagedir
Only present in project 2 and later.
unsigned magic
Always set to THREAD_MAGIC, which is just an arbitrary number defined in ‘threads/thread.c’, and used to detect stack overflow. thread_current() checks that the magic member of the running thread’s struct thread is set to THREAD_MAGIC. Stack overflow tends to change this value, triggering the assertion. For greatest benefit, as you add members to struct thread, leave magic at the end.
3.1.2.2 Understanding Threads
When a thread is created, you are creating a new context to be scheduled. You provide a function to be run in this context as an argument to thread_create(). The first time the thread is scheduled and runs, it starts from the beginning of that function and executes in that context. When the function returns, the thread terminates. Each thread, therefore, acts like a mini-program running inside Pintos, with the function passed to thread_create() acting like main().
At any given time, exactly one thread runs and the rest, if any, become inactive. The scheduler decides which thread to run next. (If no thread is ready to run at any given time, then the special “idle” thread, implemented in idle(), runs.) Synchronization primitives can force context switches when one thread needs to wait for another thread to do something.
The mechanics of a context switch are in ‘threads/switch.S’, which is 80x86 assembly code. (You don’t have to understand it.) It saves the state of the currently running thread and restores the state of the thread we’re switching to.
Using the GDB debugger, slowly trace through a context switch to see what happens. You can set a breakpoint on schedule() to start out, and then single-step from there. Be sure to keep track of each thread’s address and state, and what procedures are on the call stack for each thread. You will notice that when one thread calls switch_threads(), another thread starts running, and the first thing the new thread does is to return from switch_threads(). You will understand the thread system once you understand why and how the switch_threads() that gets called is different from the switch_threads() that returns.
3.1.2.3 Thread Functions
‘threads/thread.c’ implements several public functions for thread support. Let’s take a look at the most useful:
void thread_init (void)
Called by main() to initialize the thread system. Its main purpose is to create a struct thread for Pintos’s initial thread. This is possible because the Pintos loader puts the initial thread’s stack at the top of a page, in the same position as any other Pintos thread.
Before thread_init() runs, thread_current() will fail because the running thread’s magic value is incorrect. Lots of functions call thread_current() directly or indi- rectly, including lock_acquire() for locking a lock, so thread_init() is called early in Pintos initialization.
void thread_start (void)
Called by main() to start the scheduler. Creates the idle thread, that is, the thread that is scheduled when no other thread is ready. Then enables interrupts, which as a side effect enables the scheduler because the scheduler runs on return from the timer interrupt, using intr_yield_on_return().
void thread_tick (void)
Called by the timer interrupt at each timer tick. It keeps track of thread statistics and triggers the scheduler when a time slice expires.
void thread_print_stats (void)
Called during Pintos shutdown to print thread statistics.
tid_t thread_create (const char name, int priority, thread func func, void *aux)
Creates and starts a new thread named name with the given priority, returning the new thread’s tid. The thread executes func, passing aux as the function’s single argument.
thread_create() allocates a page for the thread’s struct thread and stack and initializes its members, then it sets up a set of fake stack frames for it. The thread is initialized in the blocked state, then unblocked just before returning, which allows the new thread to be scheduled.
void thread_func (void *aux)
This is the type of the function passed to thread_create(), whose aux argu- ment is passed along as the function’s argument.
void thread_block (void)
Transitions the running thread from the running state to the blocked state. The thread will not run again until thread_unblock() is called on it, so you’d better have some way arranged for that to happen. Because thread_block() is so low-level, you should prefer to use one of the synchronization primitives instead.
void thread_unblock (struct thread *thread)
Transitions thread, which must be in the blocked state, to the ready state, allowing it to resume running. This is called when the event that the thread is waiting for occurs, e.g. when the lock that the thread is waiting on becomes available.
struct thread * thread_current (void)
Returns the running thread.
tid_t thread_tid (void)
Returns the running thread’s thread id. Equivalent to thread_current ()->tid.
const char * thread_name (void)
Returns the running thread’s name. Equivalent to thread_current ()->name.
void thread_exit (void) NO_RETURN
Causes the current thread to exit. Never returns, hence NO_RETURN(what this macro means?).
void thread_yield (void)
Yields the CPU to the scheduler, which picks a new thread to run. The new thread might be the current thread, so you can’t depend on this function to keep this thread from running for any particular length of time.
void thread_foreach (thread_action_func action, void aux)
Iterates over all threads t and invokes action(t, aux) on each. action must refer to a function that matches the signature given by thread_action_func():
void thread_action_func (struct thread thread, void aux )
Performs some action on a thread, given aux.
int thread_get_priority (void)
void thread_set_priority (int new_priority)
Stub to set and get thread priority.
int thread_get_nice (void)
- void thread_set_nice (int new_nice)
- int thread_get_recent_cpu (void)
int thread_get_load_avg (void)
Stubs for the advanced scheduler.
3.1.2.4 Thread Switching
schedule() is responsible for switching threads. It is internal to threads/thread.c and called only by the three public thread functions that need to switch threads: thread_block(), thread_exit(), and thread_yield(). Before any of these functions call schedule(), they disable interrupts (or ensure that they are already disabled) and then change the running thread's state to something other than running.
schedule() is short but tricky. It records the current thread in local variable cur, determines the next thread to run as local variable next (by calling next_thread_to_run()), and then calls switch_threads() to do the actual thread switch. The thread we switched to was also running inside switch_threads(), as are all the threads not currently running, so the new thread now returns out of switch_threads(), returning the previously running thread.
switch_threads() is an assembly language routine in threads/switch.S. It saves registers on the stack, saves the CPU's current stack pointer in the current struct thread's stack member, restores the new thread's stack into the CPU's stack pointer, restores registers from the stack, and returns.
The rest of the scheduler is implemented in thread_schedule_tail(). It marks the new thread as running. If the thread we just switched from is in the dying state, then it also frees the page that contained the dying thread's struct thread and stack. These couldn't be freed prior to the thread switch because the switch needed to use it.
Running a thread for the first time is a special case. When thread_create() creates a new thread, it goes through a fair amount of trouble to get it started properly. In particular, the new thread hasn't started running yet, so there's no way for it to be running inside switch_threads() as the scheduler expects. To solve the problem, thread_create() creates some fake stack frames in the new thread's stack:
The topmost fake stack frame is for switch_threads(), represented by struct switch_threads_frame. The important part of this frame is its eip member, the return address. We point eip to switch_entry(), indicating it to be the function that called switch_entry().
The next fake stack frame is for switch_entry(), an assembly language routine in threads/switch.S that adjusts the stack pointer, calls thread_schedule_tail() (this special case is why thread_schedule_tail() is separate from schedule()), and returns. We fill in its stack frame so that it returns into kernel_thread(), a function in threads/thread.c.
The final stack frame is for kernel_thread(), which enables interrupts and calls the thread's function (the function passed to thread_create()). If the thread's function returns, it calls thread_exit() to terminate the thread.
We don't need to rewrite any code in this part. But we need to know how it works. Please remember that ensuring the interrupts are already disabled when we need to switch thread.
3.2 Assignment: Hello,Pintos again
3.2.1 Description
Do you remember your first homework? Now, you need to rewrite void hello_pintos(void). Before you start writing code. You need to read struct thread , Understanding Thread, Thread Functions and the whole fifith part --List.And maybe you also need to read part of Synchronization.
Before you start rewriting, you need to add some code in right place.
/* use to store integer */
struct sortNumber {
int number;
struct list_elem elem;
};
Add this struct in init.h or thread.h.
static struct list number_list;
static struct lock number_lock;
Add this part in init.c
You can start rewriting void hello_pintos(void) now.
In the new function, you need to print a message like "Hello, your name" at first. And then, you should create three threads. The first thread is used to produce some integers in random and insert them in number_list. The second thread is used to sort the number_list. The number should be in descending order. And the third thread is used to print the number after sort.
tips:
You can get random number by function void random_bytes (void *, size_t) in random.h,
Because you are asked to use multithreading to implement. You should pay attention to the order of the thread executing.You can use lock to make the thread execute in order.
Timetable of the thread execute:

You should make your program execute like single-thread.
Sample output:

I used one hundred number here.
3.2.2 Requirement
1.Read struct thread, Understanding Thread, Thread Functions and the whole fifith part --List.
2.Rewrite void hello_pintos(void) in accordance with the requirements.
3.download and fill the DESIGNDOC and archive your code(the whole pintos folder) and DESIGNDOC into a zip file named sid_nameInPinYin_vid.zip(e.g 12330441_zhangsan_v0.zip) and upload to the ftp.